Hi Ana,
Unfortunately, there’s no particularly easy solution to this challenge, which we’ve dealt with pretty consistently over the years. In addition, the solution will be quite different depending on the specifics of the construction of that ‘whole-network’. For example, are you matching alters to alters, alters to egos, all nodes to all nodes, etc. I’ve found the reclin package (GitHub - djvanderlaan/reclin: Probabilistic Record Linkage in R) to be the most useful of the various entity resolution packages in R. However, we still use clerical review after ranking the likelihood of matches.
Assuming attributes are equivalent across all nodes you’re looking to compare, here is a short example comparing last and first name to try and match nodes and also assuming the dataset is small enough where blocking is not required to reduce the number of comparisons. Work prior to this example would include cleaning name data and combining the ego and alter attribute data into a single data frame.
# Entity Resolution
compData <- pair_blocking(egoAlterData,egoAlterData)
compData <- compare_pairs(compData, by = c("firstName","lastName"),
comparator = list(jaro_winkler(0.9),jaro_winkler(0.9)),
overwrite = TRUE)
m <- problink_em(compData)
compFinal <- select_threshold(compData, "weight", var = "threshold", threshold = 6.5)
p <- score_problink(compFinal, model = m, var = "weight")
comparison <- link(p)
We’d then export the comparison data frame into a spreadsheet software and manually review matches. Typically, I’d simply create a new variable at the end of the data inputting a “0” if there is no match and a “1” if there is a match. After this, we also use double coding by two individuals and consensus for resolving disagreements.
Finally, using this manually created data, I’d assign a new ID for any instance of matches, using whatever convention works for you. This requires extra work if there are more than a single match to make sure you only assign a single ID across all matched IDs.
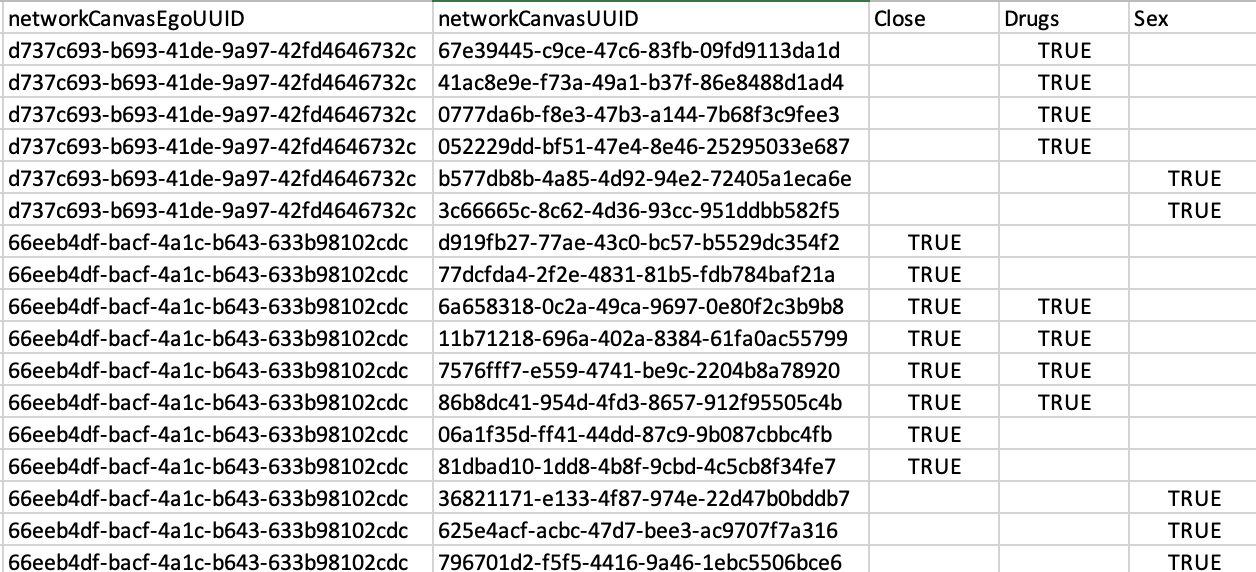
We then iterate through the edgelist data, replacing any instance of either original ID with the newly created ID. However, this process is complex if you’re including ego-to-alter edge data. As you’re likely aware, network canvas stores this in the attributeList data frame. Here is an example of such a dataset with three types of ego-to-alter ties: “close,” “drugs,” and “sex.”
If we wanted to include ego-to-alter and alter-to-alter edges, we’d have to combine this data with the alter-to-alter edgelists. For example, assume we’re only interested in close ties, this is how we’d create that data:
# Bring in ego-to-alter data
attributes <- read.csv("protocol_attributeList_Person.csv", header = TRUE)
egoToAlter_close <- attributes[attributes$Close == TRUE ,c("networkCanvasEgoUUID","networkCanvasUUID")]
# Rename before combine with alter to alter data
colnames(egoToAlter_close) <- c("networkCanvasSourceUUID","networkCanvasTargetUUID")
# Bring in alter-to-alter close data
alterToAlter_close <- read.csv("protocol_edgeList_close.csv", header = TRUE)
# Combine ego-to-alter and alter-to-alter data
allTies_close <- rbind(alterToAlter_close[,c("networkCanvasSourceUUID","networkCanvasTargetUUID")],egoToAlter_close)
Using this combined edgelist, we’d loop through and assign the new IDs from the matched data frame for any matched nodes.
Attribute data can be even more complicated and requires special consideration (e.g., if you’re matching across egos and alters you probably want to use the attribute data provided by the ego). So that would again require a bespoke solution depending on the specifics of your data and matching process.
This is obviously quite a complex process that is strongly determined by the data you’ve collected and the type of ‘pseudo whole-network’ you’re looking to create. If you run into specific questions with your implementation of this, we’d be happy to provide our thoughts.
Best,
Pat